The Greek Sign Language (GSL) Dataset
Abstract
The Greek Sign Language (GSL) is a large-scale RGB+D dataset, suitable for Sign Language Recognition (SLR) and Sign Language Translation (SLT). The video captures are conducted using an Intel RealSense D435 RGB+D camera at a rate of 30 fps. Both the RGB and the depth streams are acquired in the same spatial resolution of 848x480 pixels. To increase variability in the videos, the camera position and orientation is slightly altered within subsequent recordings. Seven different signers are employed to perform 5 individual and commonly met scenarios in different public services. The average length of each scenario is twenty sentences.
Description
The dataset contains 10,290 sentence instances, 40,785 gloss instances, 310 unique glosses (vocabulary size) and 331 unique sentences, with 4.23 glosses per sentence on average. Each signer is asked to perform the pre-defined dialogues five consecutive times. In all cases, the simulation considers a deaf person communicating with a single public service employee. The involved signer performs the sequence of glosses of both agents in the discussion. For the annotation of each gloss sequence, GSL linguistic experts are involved. The given annotations are at individual gloss and gloss sequence level. A translation of the gloss sentences to spoken Greek is also provided.

Figure 1. Example key-frames of the introduced GSL dataset.
Evaluation splits
The GSL dataset includes the 3 evaluation setups:
- a) Signer-dependent continuous sign language recognition (GSL SD) - roughly 80% of videos are used for training, corresponding to 8,189 instances. The rest 1,063 (10%) were kept for validation and 1,043 (10%) for testing.
- b) Signer-independent continuous sign language recognition (GSL SI) - the selected test gloss sequences are not used in the training set, while all the individual glosses exist in the training set. In GSL SI, the recordings of one signer are left out for validation and testing (588 and 881 instances, respectively). The rest 8821 instances are utilized for training.
- c) Isolated gloss sign language recognition (GSL isol.) - The validation set consists of 2,231 gloss instances, the test set 3,500, while the remaining 34,995 are used for training. All 310 unique glosses are seen in the training set.
| Evaluation Split | Classes | Signers | Video instances | Duration (hours) | Resolution | FPS | Type |
|---|---|---|---|---|---|---|---|
| GSL isol. | 310 | 7 | 40,785 | 6.44 | 848 x 480 | 30 | Isolated |
| GSL SD | 310 | 7 | 10,290 | 9.59 | 848 x 480 | 30 | Continuous |
| GSL SI | 310 | 7 | 10,290 | 9.59 | 848 x 480 | 30 | Continuous |
Table 1. Statistics of GSL SLR dataset.
Annotation
The annotations for both GSL SD and GSL SI are given in the following format (path | gloss sequence separated by space) example:
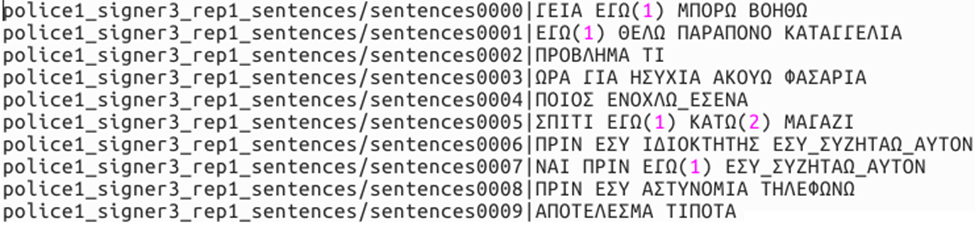
Figure 2. Example annotation for the CSLR splits.
For GSL isol. the annotations also follow a similar format (path | gloss):

Figure 3. Example annotation for the isolated split.
Benchmarking
Along with the release of the dataset we provide implementations of the best performing architectures in GSL, RWTH-PHOENIX-WEATHER 2014 and the Chinese Sign Language Recognition Dataset (CSL).
| GSL isolated | |
|---|---|
| Model | Result (%) |
| GoogLeNet+TConvs | 86.03 |
| 3D-ResNet | 86.23 |
| I3D | 89.74 |
Table 2. Results in GSL isol. Results are reported in accuracy.
| GSL SD | ||
|---|---|---|
| Model | Evaluation subset | Test subset |
| SubUNets | 52.79 | 54.31 |
| GoogLeNet+TConvs | 38.92 | 42.33 |
| 3D-ResNet | 57.88 | 61.64 |
| I3D | 49.89 | 49.99 |
Table 3. Reported results for GSL SD, measured in WER.
| GSL SI | ||
|---|---|---|
| Model | Evaluation subset | Test subset |
| SubUNets | 21.65 | 20.62 |
| GoogLeNet+TConvs | 6.99 | 6.75 |
| 3D-ResNet | 25.58 | 24.01 |
| I3D | 6.63 | 6.10 |
Table 4. Reported results for GSL SI, measured in WER.
Download
You can download the dataset from here. To download additional depth information for this dataset, click here.
Acknowledgments
This work was supported by the Greek General Secretariat of Research and Technology under contract Τ1ΕΔΚ-02469 EPIKOINONO. The authors would like to sincerely thank their collaborators, Prof. Dimitris Papazachariou, Prof. Klimnis Atzakas, George J. Xydopoulos, and Vassia Zacharopoulou, from the department of Philology of the University of Patras, who provided their meaningful insights and expertise that greatly assisted this research. We would also like to express our gratitude to the Greek sign language center for their valuable feedback and contribution on the Greek sign language data capture.
Publication
Please cite our work using the citation below:
@article{adaloglou2020comprehensive, title={A Comprehensive Study on Sign Language Recognition Methods}, author={Adaloglou, Nikolas and Chatzis, Theocharis and Papastratis, Ilias and Stergioulas, Andreas and Papadopoulos, Georgios Th and Zacharopoulou, Vassia and Xydopoulos, George J and Atzakas, Klimnis and Papazachariou, Dimitris and Daras, Petros}, journal={arXiv preprint arXiv:2007.12530}, year={2020} }
Contact
For issues regarding the dataset please contact us in the following e-mails:
- adaloglou(at)iti(dot)gr
- papastrat(at)iti(dot)gr
- andrster(at)iti(dot)gr
- hatzis(at)iti(dot)gr